
Utilisation de métadonnées pour le référencement
 Au cours d’un précédent article nous avons mené une expérience sur l’utilisation de tirets ou de underscores dans l’usage des mots clés.
Au cours d’un précédent article nous avons mené une expérience sur l’utilisation de tirets ou de underscores dans l’usage des mots clés.
Poursuivons dans cette voie, et voyons aujourd’hui comment les moteurs de recherche explorent le contenu HTML de la page et surtout, comment ils perçoivent les méta-données.
Voyons comment les moteurs arrivent, ou pas, à localiser les mots clés qui sont placés dans certaines balises ou dans des parties du document prévues pour recevoir d’autres ensembles de données.
Pour mener à bien ces expériences, nous allons une fois encore faire appel à des mots clés que les moteurs ne connaissent pas au préalable et nous allons directement les injecter dans des balises particulières du HTML, ou dans certaines facettes du document. Pour des besoins de cohérences, certaines parties de l’article précédent ont étés rapportés dans ce présent article.
Avant d’aller plus loin… comme dirait l’autre… tsoukomincka !
Avant d’aller plus loin, il faut commencer par nous assurer que cette page est bien référencée par les moteurs de recherche sur lesquels nous allons nous appuyer pour mener à bien cette expérience. Donc recherchons le mot tsoukomincka, d’abord sur Google, puis ici sur Bing.
Si les pages de résultats restent muettes ce n’est pas la peine de tester les prochaines expériences, par contre si un résultat se fait connaitre…alors en avant… n’attendons plus et explorons…
Les balises <meta /> et le référencement
Le HTML nous fournit tout un ensemble de propriétés caractérisant le document accessible au travers de la balise <meta />. Notez que bien que le w3c ne précise pas une liste définie de propriétés disponibles pour la balise <meta />.
Cette liste ne se limite pas à simplement décrire les keywords, ou la description qui en sont les deux plus connues. Vous trouverez un éventail d’autres possibilités sur le site de developpementweb.online. Pour les besoins de cet article, nous avons renseigné les propriétés Keywords, Description et Author.
Afin de pouvoir isoler l’expérience au maximum, les mots clés utilisés dans ces balises ne seront pas directement employés dans cet article (ce qui peut également porter à controverse, car, si le mot n’est pas urtilisé dans la page, pourquoi un moteur de recherche devrait-il le considérer comme un mot clé potentiel ?… pour l’instant gardons cette expérience tel quelle et essayons d’envisager une autre approche).
Pour les connaitre, il vous faut appeler le code source de la page. Dans ce but, si vous êtes sur :
- Internet Explorer et si le menu du navigateur n’est pas présent, appuyez sur la touche alt du clavier, puis dans le menu de l’application sélectionnez Affichage > Source,
- Firefox sélectionnez Affichage > Code source de la page,
- Safari, rendez-vous sur l’icône fichier et sélectionnez Code Source dans le menu déroulant qui s’ouvre…
- enfin, si vous utilisez Opéra sélectionnez Afficher > Source.
Une fois dans le code source de la page, utilisez l’outil de recherche interne au navigateur (Ctrl-Cmd F) ou lisez directement le code au début de la page pour y localiser les balises <meta name= »keyword »… et <meta name= »description ».
Récupérez alors les mots clés utilisés dans la partie content= » » . Vous pouvez ensuite lancer diverses recherches sur ces mots depuis Google et Bing.
Cette expérience vaut tous les discours pour constater que les moteurs prennent ou non en compte les contenus de ces balises :
<meta name="keywords" content="" /> <meta name="author" content="" /> <meta name="description" content="" />
L’utilisation de Dublin Core au sein des balises <meta />
Le principe des méta données est de permettre, ou de faciliter, l’injection de données décrivant un document au sein même du document. Un petit problème peut cependant survenir si par exemple, un éditeur utilise le terme de ‘Author’ pour identifier l’auteur du document et un autre outil de lecture, lui, utilise le terme de ‘Creator’… Les deux outils ne pourraient alors pas juxtaposer les deux propriétés comme étant identiques.
Pour remédier à ce genre de situation d’étiquetage divergent, il existe des standards, et notamment le Dublin Core. Le Dublin Core décrit les propriétés mais pas la manière de les utiliser, donc nous pouvons exprimer les métadonnées Dublin Core à l’aide des balises <meta /> du HTML.
Dans un premier temps regardons la liste de propriétés disponibles et parmi elles isolons en quelques unes que nous allons tester, par exemple dc.title, dc.keywords, dc.description et dc.creator.
Puce et média utilisant une plateforme Joomla, afin de simplifier l’implémentation de ces balises, nous allons externaliser une page HTML distincte meta-dublin-core.html afin de mettre cette expérience en pratique :
<meta name="DC.title" lang="fr" content="" /> <meta name="DC.subject" lang="fr" content="" /> <meta name="DC.creator" lang="fr" content="" /> <meta name="DC.description" lang="fr" content="" />
<meta name= »title » />, <meta name= »dc.title » /> ou <title> ?
La balise <meta name= »title » /> n’existe pas, ou du moins n’est pas recensée dans les listes qui énumèrent l’ensemble des propriétés disponibles pour cette balise. Toutefois, rien ne nous empêche de tester sa récupération par les moteurs de recherche.
Nous pouvons même pousser le test un tantinet plus loin en se posant la question suivante : Est ce que le moteur de recherche favorise l’une ou l’autre des méthodes qui nous permettent d’indiquer le titre d’un document ? Bien entendu de la balise d’en tête <h1>.
Donc, qu’avons-nous sous la main ? Et bien, dans un premier temps nous avons la balise mise en place précédemment <meta name= »title » />, mais aussi sa consœur, cette fois-ci officielle et fournie par le standard Dublin Core <meta name= »dc.title » />.
Nous pouvons également dans un second temps, définir la balise HTML <title>, qui après tout existe dans ce sens, donner un titre au document. Nous pouvons utiliser le même document que pour l’étape précédente meta-dublin-core.html, et nous vous invitons à le parcourir pour mener à bien cette expérience.
XMP, bien que propriétaire à l’origine, peut-il devenir un standard reconnu ?
Afin de répondre à des besoins de descriptions de fichiers, Adobe a mis en place le XMP (Adobe Extensible Metadata Platform). Cette technologie open source permet à toute application qui prend en charge XMP de parcourir les métadonnées contenues.
Par ailleurs, de part sa grammaire XML, XMP est extensible et de ce fait, il peut facilement accueillir des schémas de métadonnées existantes.
Aujourd’hui, l’ensemble des applications Adobe intègre cette technologie et d’autres groupes de travail sur les standards se penchent sur XMP. Avant que l’avenir nous dise ce qu’il en adviendra, voyons voir ce qu’en pensent d’ores et déjà les moteurs de recherche ?

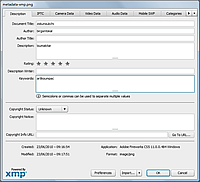 metadata-xmp.png Pour mettre en place ce test, un fichier Fireworks a été mis en place spécialement pour l’occasion. Ce fichier ne contient qu’une simple illustration d’un rectangle… cool non ?… Par contre, il est truffé de mots clé dans sa partie description XMP avec des champs comme title, description, author et keywords.
metadata-xmp.png Pour mettre en place ce test, un fichier Fireworks a été mis en place spécialement pour l’occasion. Ce fichier ne contient qu’une simple illustration d’un rectangle… cool non ?… Par contre, il est truffé de mots clé dans sa partie description XMP avec des champs comme title, description, author et keywords.
Pour connaitre les mots clés employés, cliquez simplement sur l’image qui représente la boite de dialogue ci-dessus. Vous les verrez alors apparaître dans leur champs respectifs.