
Présentation et introduction aux technologies serveur
 Les relations client serveur
Les relations client serveur
Que l’on soit sur PC, Macintosh, téléphonie mobile, assistant personnel,… ou tout autre support électronique et que, depuis un navigateur (ou une interface assimilée) on se connecte au Web, nous sommes en position de poste client.
À ce moment là, utilisant le protocole HTTP, une requête de type http://www.adresse.com est envoyée au poste serveur. Dans le cas le plus élémentaire, la page sollicitée est une page .htm ou .html, le serveur va alors se contenter de la récupérer sur un de ses disques durs et l’envoyer au poste client demandeur.
Une première relation client / serveur vient de s’établir. De son côté, le navigateur, lorsqu’il reçoit la page, l’analyse et affiche au fur et à mesure son contenu. A chaque fois que dans le code HTML est rencontré une autre requête HTTP, le procédé recommence et l’information retourne sur le serveur afin de récupérer les nouvelles informations (par exemple, des feuilles de styles, des images, des animations flash, des scripts, etc…).
Quelle soit appelée aujourd’hui ou demain, depuis un client A ou un client B… peu importe, la page sera toujours identique et il faudra modifier physiquement son contenu HTML, afin de modifier les informations qu’elles présente et qui sont renvoyées.
Les seules modifications qui peuvent alors intervenir, sont des modifications liées à l’interaction de l’utilisateur, par exemple lorsque celui-ci survole un bouton, rempli un formulaire, ou cliques sur une zone particulière… A ce moment-là, le navigateur est à même de pouvoir interpréter un certain degré d’interactivité, grâce au langage JavaScript.
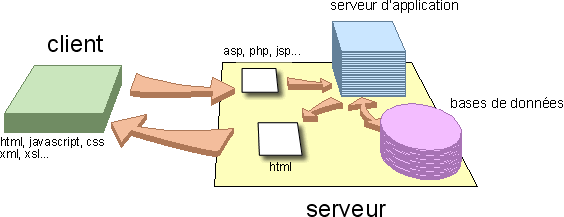 Dans le cas où la page sollicitée est une page .asp, .php, .jsp, .cfml, .cgi etc…, le serveur Web en réfère alors au serveur d’application, qui va alors interpréter le code ASP, PHP, JSP, CFML ou CGI… et celui-ci retournera alors du code HTML. Cela sera ce code HTML généré qui sera alors retourné au poste client.
Dans le cas où la page sollicitée est une page .asp, .php, .jsp, .cfml, .cgi etc…, le serveur Web en réfère alors au serveur d’application, qui va alors interpréter le code ASP, PHP, JSP, CFML ou CGI… et celui-ci retournera alors du code HTML. Cela sera ce code HTML généré qui sera alors retourné au poste client.
Il se peut également que ce code serveur fasse référence à des requêtes SQL. Ces requêtes permettent d’interroger des bases de données et donc, d’ajouter du contenu nouveau, et distinct, à la page HTML générée, telles que des informations provenant d’un catalogue, d’un référentiel ou encore de tout autre système d’indexation de l’information.
Il va de soit que dans la majeure partie des situations, ces requêtes SQL sont modifiées par des paramètres provenant directement du poste client. Par exemple, sous la forme de http://www.serveur.com/page.asp?ar=12&lg=fr. De cette manière, et à la différence de simple page HTML, en fonction de la requête initiale, des dizaines de pages différentes peuvent être reçues par le poste client.
1 réponse
[…] Tout semble paré, nous avons vu l’outil de codage, quelques librairies ou frameworks, des outils d’aide à l’écriture de code et des automatisuers de tâches… tout est là ou presque, car cela reste uniquement des technologies clients, et grand nombre de sites ou d’applications web s’appuient encore et toujours sur des serveurs. Donc il nous faut également caler un environnement serveur. Travailler en local mais sur un serveur, voir à ce sujet Présentation et introduction aux technologies serveur. […]